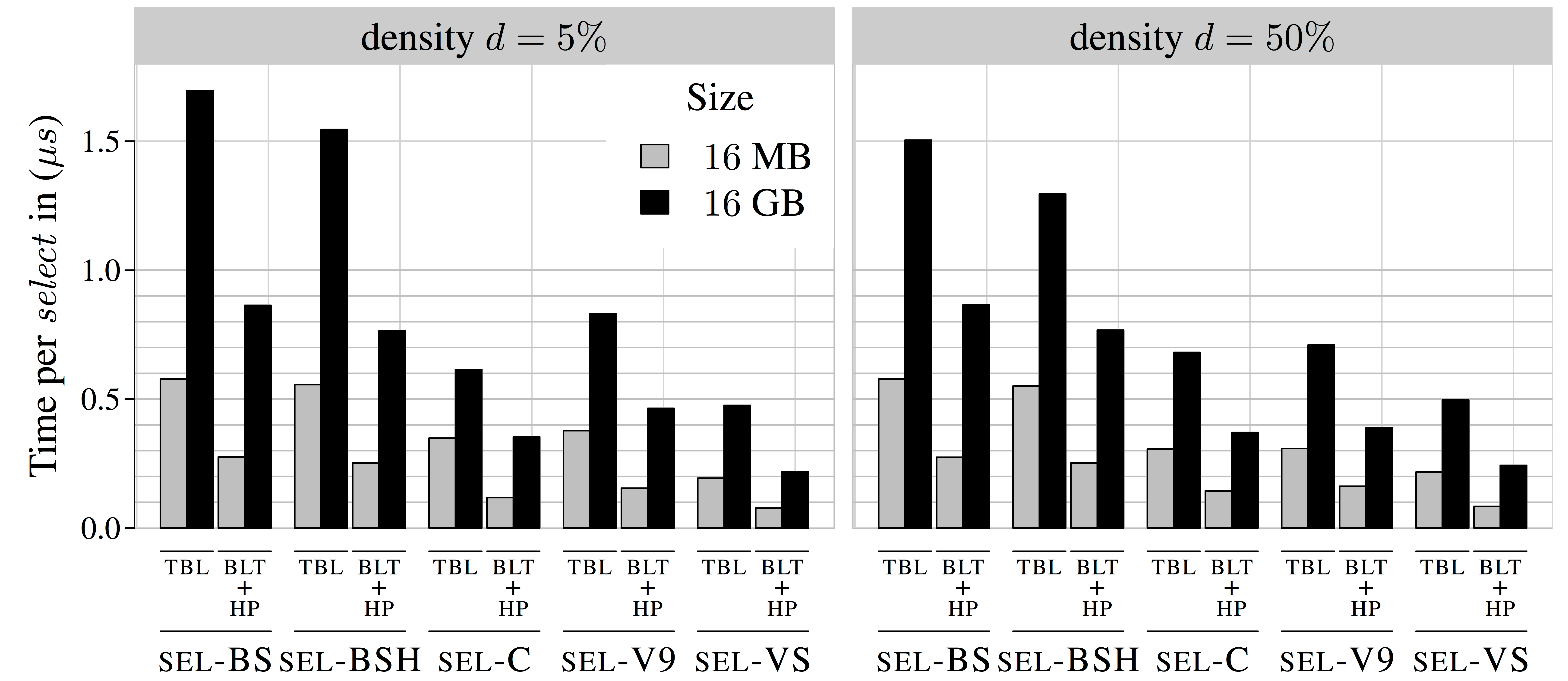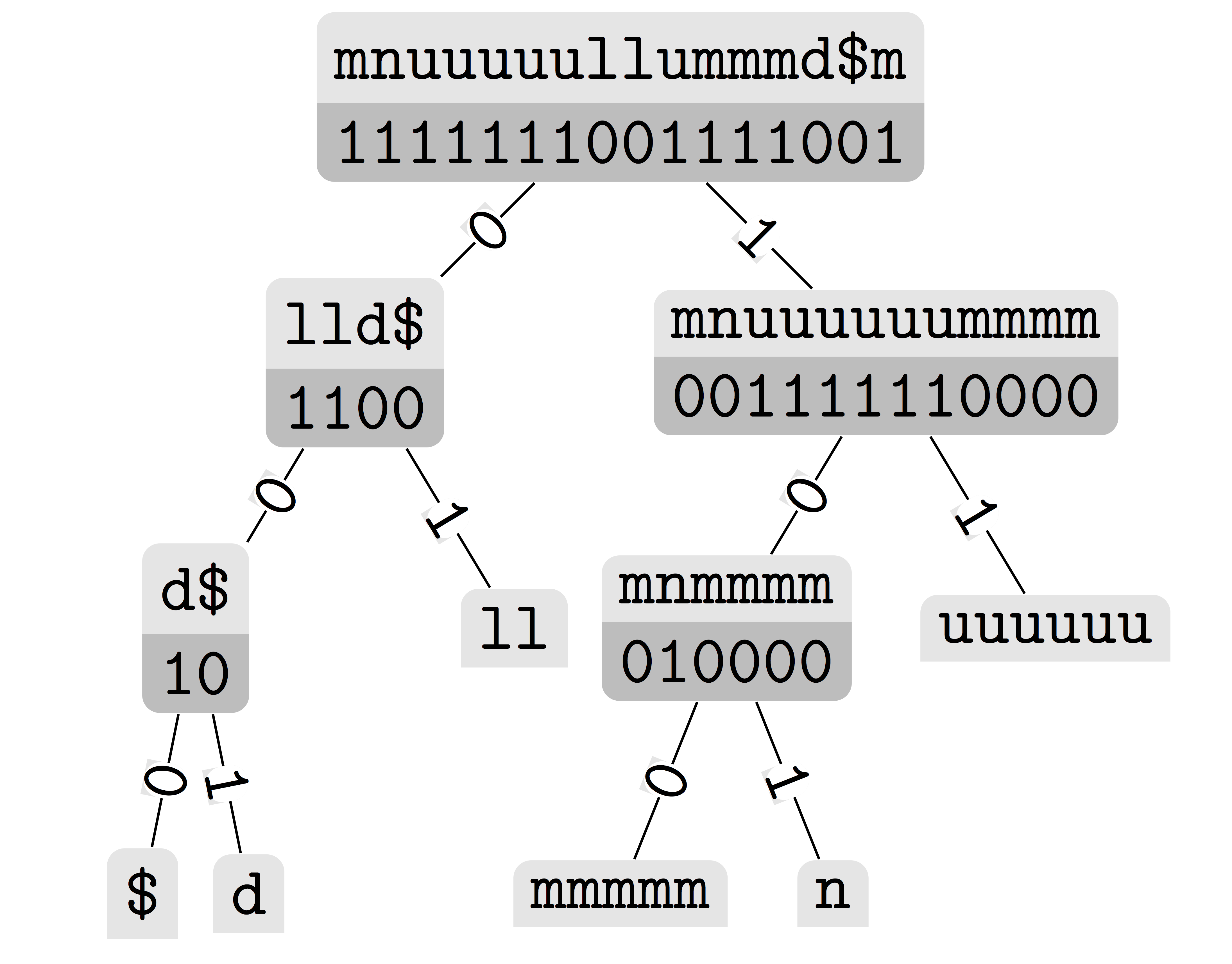Goal: Provide an easy-to-use, highly-efficient, configurable, and extensible library of succinct data structures for researchers and practitioners.
It is/was a challenge to meet all this goals. Here is the current state:
- C++ is used (great for resource-constraint programming).
- Templates are used to make it configurable.
- STL concepts are used to make it easy-to-use.
- Space and time efficient construction using the semi-external approach.
- Construction is configurable between in-memory and semi-external.
- All indexes support byte and integer sequences.
- Implements highlights of 40 research articles.
Development by Timo Beller, Matthias Petri, me, and others.